
- Published on
Blocking Queue를 이용해서 Producer-Consumer 패턴 구현하기
- Authors

- Name
- Chan Sol OH
목차
- 소개
- producer-consumer 패턴 문제점
- producer-consumer 패턴을 왜 써요?
- 실생활에 쓰이는 예시
- 간단한 구현 예시 - 카운터
- 브로커와 이벤트 정의
- 프로듀서 정의
- 컨슈머 정의 - 1차
- 테스트
- 컨슈머 리팩토링
- 문제의 원인 1 - 카운터 결과 값을 읽을 수 있는 시점과 컨슈머 작업 종료 시점의 불일치
- 문제의 원인 2 - 프로듀서의 작업 생성 속도와 컨슈머의 작업 처리 속도 차이
- 컨슈머 정의 - 최종
- 결론
- 참고
소개
서로 다른 두 컴포넌트가 강하게 결합될 때, 한 컴포넌트의 예외가 다른 컴포넌트로 전달될 수 있다. 두 컴포넌트의 결합을 느슨하게 하는 방법 중 하나로 producer-consumer 패턴을 이용할 수 있다. producer는 데이터나 이벤트를 생성하고 consumer는 생성된 데이터나 이벤트를 처리한다.
모든 코드는 spring-concurrency-thread에 있습니다. 또한 테스트 코드는 test에 있습니다.
producer-consumer 패턴 문제점
Producer-Consumer는 멀티스레드 환경에서 동기화 관점에서 문제가 발생한다. 멀티스레드가 동시에 데이터를 생성하고 버퍼(메세지 큐)에 저장한다. 또 멀티스레드가 동시에 데이터를 버퍼에서 떠내 사용한다.
몇가지 위험한 시나리오가 있는데 첫번째로 버퍼에 저장할 때 발생한다. 버퍼가 스레드 안전하지 않다면, producer 스레드들의 데이터 쓰기가 동시에 이뤄지다 보면 스테일 데이터를 큐에서 읽고 이를 바탕으로 업데이트하기 때문에 제대로 데이터가 저장되지 않는 경우가 있을 수 있다. 또는 consumer 스레드들이 데이터를 동시에 읽는다면 스테일 데이터를 읽어서 똑같은 작업을 두번하게 되는 일이 발생할 수 있다.
이처럼 동시성의 흔한 문제점을 가지고 있다.
producer-consumer 패턴을 왜 써요?
가장 큰 장점은 확장성에 있다. 메세지 큐만 버틸 수 있다면, producer와 consumer를 계속 늘릴 수 있고, 이 말은 이벤트 생성 속도와 이벤트 처리 속도를 늘릴 수 있다는 것이다. 또한 큰 장점은 내결함성이다. 메세지 큐를 사이에 두고 producer와 consumer가 분리되어 있어서 producer와 consumer를 교체하거나 재시작할 수 있어서 내결함성을 허용한다.
실생활에 쓰이는 예시
- Web Server (Nginx)
- Message Queue (AWS SQS)
- Data Processing
간단한 구현 예시 - 카운터
카운터 예제는 흔한 동시성 예제로 등장한다. 책에선 데스크탑 검색 예제가 있지만, Spring 템플릿 프로젝트의 시나리오인 카운터를 위해 구현해본다. 구성은 producer가 카운팅 이벤트를 Blocking Queue에 저장하면, consumer가 Blocking Queue에 이벤트를 읽고 카운팅을 하는 구조다.
브로커와 이벤트 정의
가장 먼저 Blocking Queue에 들어갈 이벤트 클래스를 만들어 준다. 이를 위해 java8부터 가능한 함수형 인터페이스를 이용해 일급함수를 Queue에 저장하려고 한다. 요구사항은 기존 카운트 값에 int 값을 더해 카운트 값을 업데이트하는 것이기 때문에 Function을 사용한다.
BlockingQueue를 관리하는 브로커를 아래처럼 작성했고, github 커밋은 여기다.
public class CounterBroker {
// 최대 1000개의 이벤트를 저장할 수 있다.
private final BlockingQueue<Function<Integer, Integer>> queue = new LinkedBlockingQueue<>(1000);
public void addEvent(int value){
try{
// 이 이벤트를 컨슈머가 처리할 당시 count와 value를 더한 값을 출력한다.
queue.put((c) -> c+value);
}
catch(InterruptedException e){
Thread.currentThread().interrupt();
}
}
public Function<Integer, Integer> take(){
try {
return queue.take();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
프로듀서 정의
프로듀서는 브로커에게 이벤트를 입력해달라고 요청한다.
public class CounterProducer {
private final CounterBroker counterBroker;
public CounterProducer(CounterBroker counterBroker) {
this.counterBroker = counterBroker;
}
public void add(int value){
counterBroker.addEvent(value);
}
}
컨슈머 정의 - 1차
컨슈머는 카운터를 관리하며 이벤트를 큐에서 가져와서 카운터를 업데이트한다. 컨슈머는 while 문을 돌면서 큐에 이벤트가 있는지 확인하고 있을 때까지 대기하다가 이벤트가 생기면 뽑아와서 덧셈 연산을 한다.
public class CounterCustomer {
private final CounterBroker counterBroker;
private AtomicInteger count = new AtomicInteger(100); // AtomicInteger로 변경
public CounterCustomer(CounterBroker counterBroker) {
this.counterBroker = counterBroker;
}
public void consumEvent(){
while(true){
Function<Integer,Integer> event = counterBroker.take();
IntUnaryOperator operator = event::apply;
count.updateAndGet(operator); // 원자적인 연산 보장하기 위함
}
}
public int show(){ // 스레드 안전하게 카운트 결과를 출력한다.
// AtomicInteger의 get 메서드를 사용하여 값을 가져옴
return count.get();
}
}
단순하게 생각하면 카운터를 AtomicInteger 타입을 사용했으니 스레드 안전하겠지만, 아래 테스트 결과를 보면 알겠지만 실패한다. 그 이유는 2차에서 자세히 다루겠다.
테스트
테스트는 3개의 컨슈머 스레드 그리고 최대 15개의 프로듀서 스레드가 실행되어 10000개의 이벤트를 생성 및 처리한다.
public class QueueCounterTest {
private final int counteNumber = 1;
private final int totalCount = 10000;
private static final Logger logger = LoggerFactory.getLogger(SynchronizedCounterTest.class);
@Test
@DisplayName("producer consumer 패턴을 이용해서 더하기 이벤트 발생 스레드와 더하기 이벤트 처리 스레드를 분리하자")
public void 프로듀서_컨슈며_더하기_멀티_프로듀서_멀티_컨슈머() throws InterruptedException {
CounterBroker counterBroker = new CounterBroker();
CounterCustomer customer = new CounterCustomer(counterBroker);
CounterProducer producer = new CounterProducer(counterBroker);
LocalTime lt1 = LocalTime.now();
int initalCount = customer.show();
ExecutorService service = Executors.newFixedThreadPool(15);
CountDownLatch latch = new CountDownLatch(totalCount);
// CounterCustomer 스레드 생성 및 비동기로 처리 시작
for(int i=0; i<3; i++){
CompletableFuture.runAsync(customer::consumEvent);
}
// 프로듀서 스레드 생성
for (int i = 0; i < totalCount; i++) {
service.submit(() -> {
producer.add(counteNumber);
latch.countDown();
});
}
latch.await();
int finalCount = customer.show();
LocalTime lt2 = LocalTime.now();
long dif = Duration.between(lt1, lt2).getNano();
logger.info("프로듀서_컨슈며_더하기_멀티_프로듀서_단일_컨슈머 테스트가 걸린 시간 : " + dif / 1000 + "ms");
Assertions.assertEquals(initalCount + totalCount*counteNumber, finalCount);
}
}
expected: <10100> but was: <10096>
...
at com.thread.concurrency.counter.QueueCounterTest.프로듀서_컨슈며_더하기_멀티_프로듀서_멀티_컨슈머(QueueCounterTest.java:53)
컨슈머 리팩토링
문제의 원인 1 - 카운터 결과 값을 읽을 수 있는 시점과 컨슈머 작업 종료 시점의 불일치
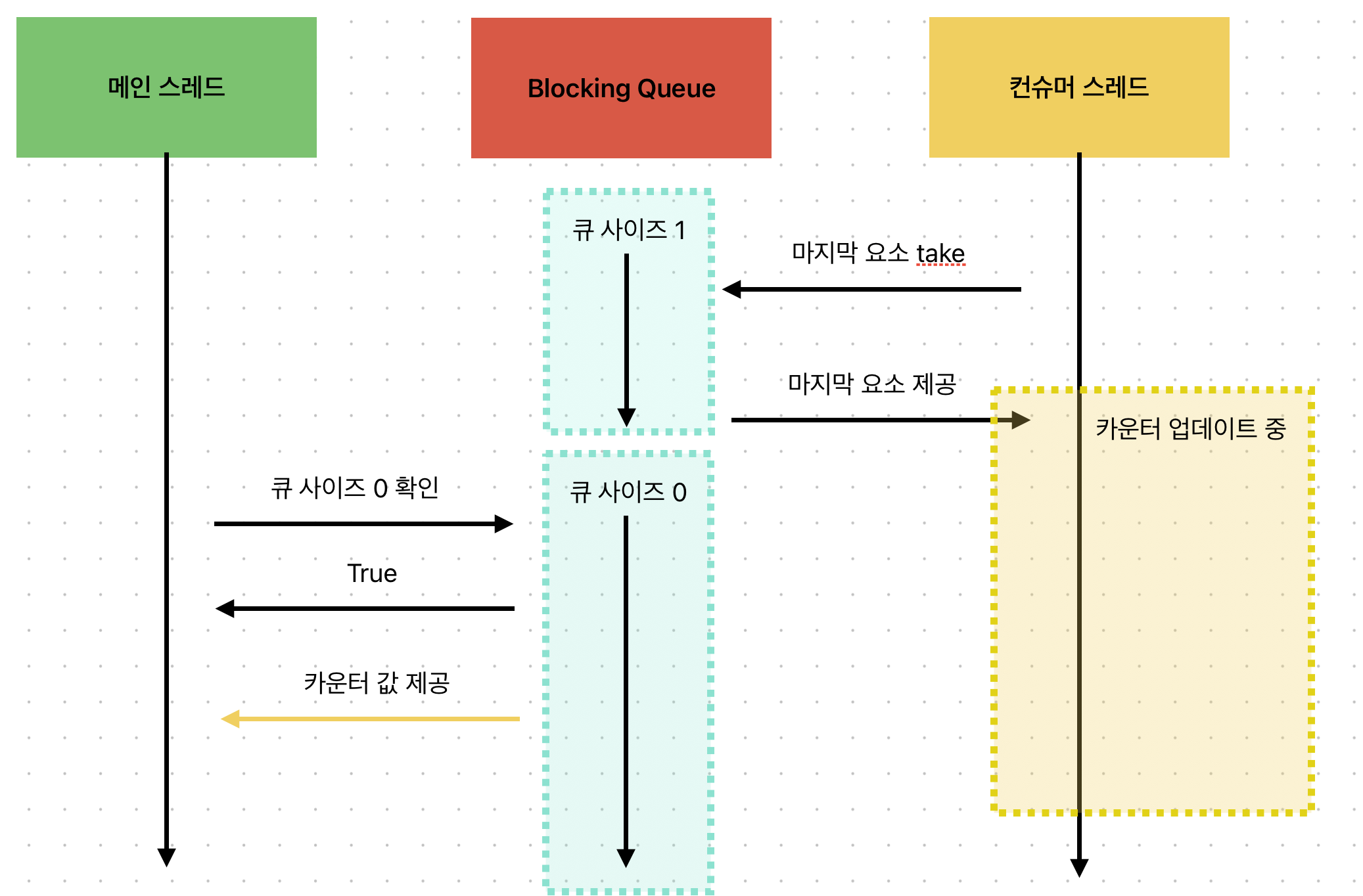
카운터를 읽을 수 있지만, 컨슈머는 카운터를 업데이트 하고 있었다.
코드를 보면 컨슈머가 영원히 while 문을 돌면서 작업을 진행한다. 이럴 경우 Test를 하거나 작업을 맡길 때 끝났는지 정확하게 알 수 없다. CounterCustomer.show 메서드를 보면, 단지 큐의 사이즈만 보고 카운터를 관측한다. 하지만, 큐가 비어있다고 무조건 컨슈머의 모든 작업이 끝남을 보장할 수 있을까?
그럴 수 없다. 컨슈머는 모든 작업을 끝냈다고 알려준적이 없다. 단지 큐에서 작업을 빼갔고, 컨슈머 스레드의 작업이 미처 끝나기 전에 main 스레드가 show 메서드를 실행시킨 것 뿐이다. 그 결과 show의 출력에는 스테일 데이터가 나오게 된다.
그림으로 보면 아래 같은 상황인 것이다.
문제의 원인 2 - 프로듀서의 작업 생성 속도와 컨슈머의 작업 처리 속도 차이
위 원인을 해결하고자 컨슈머를 아래 같이 수정했다. 코드는 여기에 있다.
public class CounterConsumer {
...
public void consumeEvent() throws InterruptedException {
while (!queue.isEmpty()) {
System.out.println(Thread.currentThread().getName()+"은 현재 큐 사이즈 : "+queue.size());
Long value = queue.take();
// count.addAndGet(value);
System.out.println("결과 카운트 : "+count.addAndGet(value));
}
}
public Long show(){
while(true){
if(queue.isEmpty()){
return count.get();
}
}
}
}
위처럼 컨슈머를 작성하고 실행시키면, 테스트에 명시한 카운트 증가가 이뤄지지 않았는데 모든 컨슈머가 작업을 종료하고 큐에는 다시 작업이 쌓이게 된다. 프로듀서는 작업을 추가할 때 큐의 용량이 다 차면 자리가 날 때까지 대기하기 때문에 끝나지 않고 종료도 되지 않는다. 그렇기 때문에 컨슈머가 작업을 종료하는 기준을 다시 세워야한다.
단순히 큐가 비었냐로 판단하지 않는다면 어떻게 판단할 수 있을까?
프로듀서와 컨슈머가 flag로 통신하기
프로듀서가 컨슈머의 flag를 바꾸면서 flag가 true면 컨슈머가 작업을 계속 진행하고 flase면 작업을 멈추게하는 방식이다. 이런 방식의 장점은 구현의 간단함이 있다. 하지만, 작업의 생성과 수행의 의존성을 낮추는 목적인 프로듀서-컨슈머 패턴에서 이런 방식은 두 모듈을 의존하게 만드는 것이기 때문에 본질과 멀어진다.
컨슈머가 작업을 잠시 대기하기 프로듀서와 컨슈머를 독립적으로 유지하면서 큐가 비어있더라도 컨슈머가 계속 작업을 하기위해선, 컨슈머가 큐가 비었더라고 잠시 대기하는 방식을 쓸 수 있다. 이를 위해
BlockingQueue poll()메서드를 사용할 수 있다.
컨슈머 정의 - 최종
public class CounterConsumer implements Consumer {
private final BlockingQueue<Long> queue;
private final AtomicLong count = new AtomicLong(0);
public CounterConsumer(BlockingQueue<Long> queue) {
this.queue = queue;
}
public void consumeEvent(long timeout, TimeUnit unit) throws InterruptedException {
while (true) {
Long value = queue.poll(timeout, unit);
if(value == null){
break;
}
count.addAndGet(value);
}
}
public Long show(){
while(true){
if(queue.isEmpty()){
return count.get();
}
}
}
}
위와 같이 consumeEvent는 무한히 작업을 진행하지만, 큐가 빌때 timeout 시간 동안 대기한다. 컨슈머가 대기하는 동안 프로듀서가 큐에 작업을 넣는다면, 컨슈머가 다시 작업을 시작하고 그렇지 않다면 컨슈머는 null을 반환하고 작업을 끝내게 된다.
모든 컨슈머가 작업을 끝낸걸 어떻게 알 수 있을까? CountDownLatch를 이용하면 모든 컨슈머 스레드가 작업을 끝낼 때까지 대기할 수 있다.
...
// 컨슈머 스레드 생성
consumerService.submit(() -> {
try {
consumer.consumeEvent(timeout, unit);
consumerLatch.countDown();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
consumerLatch.await(); // 모든 컨슈머 스레드가 작업을 끝낼 때까지 대기
...
결론
길고긴 삽질 끝에 BlockingQueue를 이용해 프로듀서-컨슈머 카운터를 구현했다. 프로듀서-컨슈머 패턴은 서로 다른 역할을 하는 모듈의 의존성을 낮출 때 사용한다고 한다. 특히 버퍼링 통신, 데이터 수집 및 처리, 큐 메시지 처리 같은 분야에서 자주 사용되는 프로듀서-컨슈머 패턴을 구현해보면서 앞으로 프로젝트에서 자주 사용할 것 같다.
느낀 점은 프로듀서와 컨슈머를 만드는 것도 동시성을 고려하면서 이 둘을 사용하는 부분 여기서는 QueueCounterTest.java도 중요함을 느꼈다. 프로듀서 컨슈머의 스레드를 적절하게 분배하고 타임아웃이나 큐 케페시터 등 여러 파라미터를 지정하기 때문이다.
멀티스레드 작업은 운영 환경에 따라 다른 파라미터가 필요할 것 같다. Macbook Air M2 환경에서 Test 할 때 5억개의 작업을 큐에 넣고 뺐는데, 시간이 30초 정도로 시간이 오래 걸렸다. 물론 스레드 개수나 케페시터 사이즈에 따라 다양한 결과가 있을 것이다. 프로젝트에서 프로듀서-컨슈머 패턴을 사용한다면 단순 구현 뿐 아니라 실제 요청과 가장 유사한 테스트에서 시간이 가장 짧게 걸리는 파라미터를 찾는데 시간을 많이 쏟을 것 같다.
참고
- Producer Consumer Solution using BlockingQueue in Java Thread
- System Design Patterns: Producer Consumer Pattern
- 자바 병렬 프로그래밍 5장 블로킹 큐와 프로듀서-컨슈머 패턴