
- Published on
Spring JPA의 계층 구조
- Authors

- Name
- Chan Sol OH
목차
- DB Table에 대한 Query - JDBC
- Entity에 대한 Query
- Persistence
- JPQL (java Persistence query language)
- JPA 인터페이스의 3요소
- JPA 장점
- Hibernate = JPA 구현체
- Spring Data JPA
- Query Method 기능
- Custom Query Method
- 반환 타입
- Query DSL
- (번외) ORM vs SQL Mapper
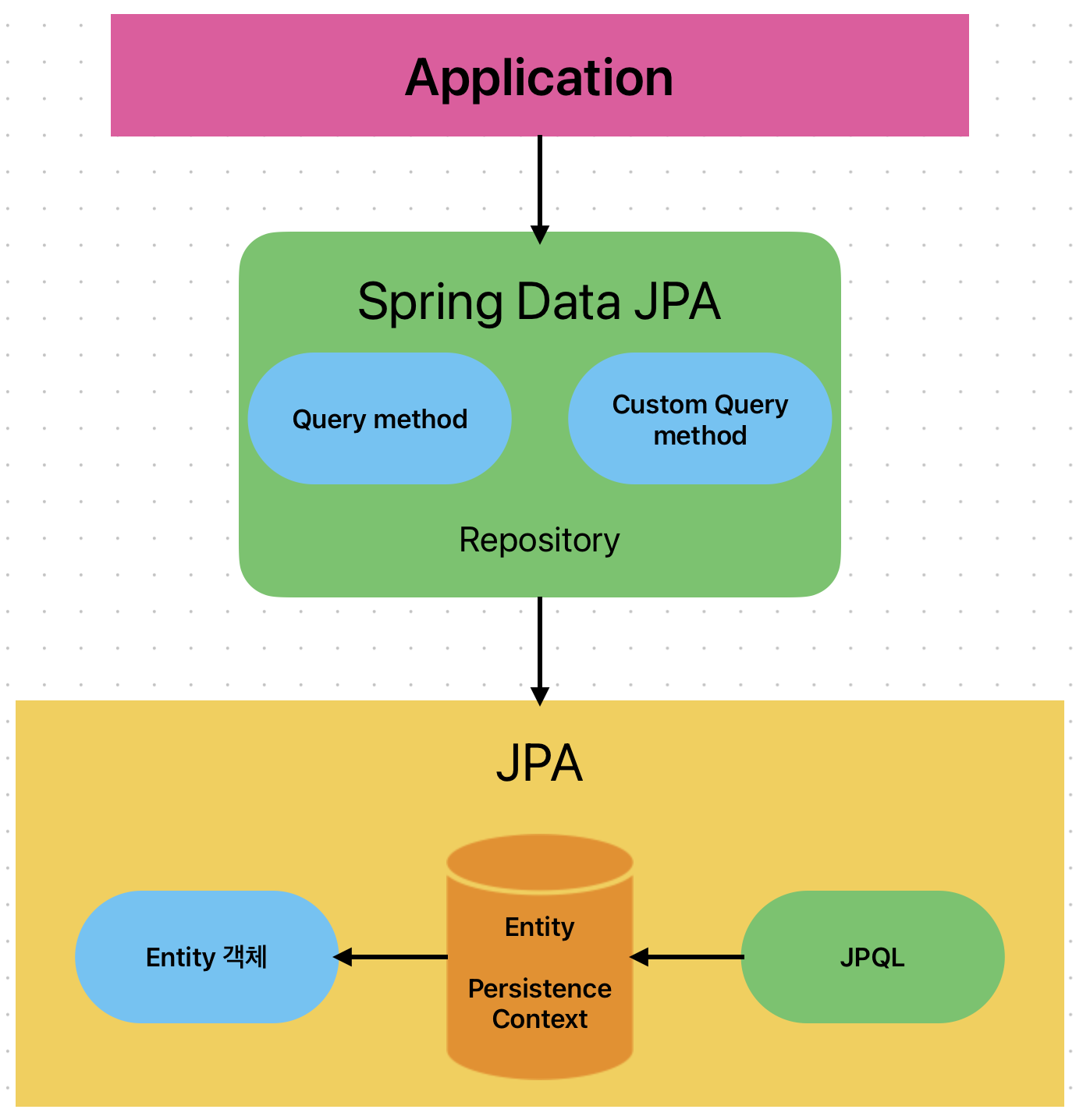
DBMS, JDBC Driver, JDBC APIs, JDBC Templatem, JPA, 그리고 Spring Data JPA까지 DB transaction을 추상화하는 과정을 계층적으로 정리하는 포스팅 JDBC Template까지는 JDBC 개념정리에 작성해놨다. 아래는 JPA의
DB Table에 대한 Query - JDBC
JDBC Template이나 SqlMapper는 DBMS에 맞는 Native 쿼리를 직접 작성했다. 단순히 JDBC API를 개발자가 쿼리와 row mappeing만 작성하도록 추상화한 것이다. 하지만 이렇게 Native 쿼리를 작성하는 것은 DBMS에 종속적이다.
JDBC처럼 DB를 직접적으로 사용한다면 트랜잭션에대한 관리를 개발자 개인이 신경써야한다. 일일히 원하는 쿼리문을 Native하게 작성해야한다. **결과(ResultSet)**에 대한 **매핑 함수(RowMapper)**를 정의해야, 객체로 사용할 수 있다. 또한 [객체 모델과 관계형 모델] 사이의 매핑 이슈가 있다.
위와 같은 이슈를 해결하기 위해 ORM으로 객체모델과 관계형 모델을 자동으로 매핑하고, Entity 객체에 대한 조작 결과가 DB로 적용될 수 있게한다.
Entity에 대한 Query
JPA는 Java의 객체 모델을 자동으로 매핑해주는 ORM 기술에 대한 Java 표준 명세. JDBC처럼 직접 SQL문을 사용하지 않고, Java Entity 객체에 대한 JPQL 문을 통해 DB에 간접 접근, 조작 내부적으로 JDBC Template을 사용한다.
Persistence
매번 데이터베이스에 연결하고 쿼리를 보내지 않고 EntityManager를 통해 메모리(Persistence Context) 상에 작업을 한후 트랜잭션이 커밋되는 시점에 데이터베이스에 반영하는 구조
Persistence Context
- JPA가 Entity 객체들을 모아두고 CRUD하는 논리적인 공간
- transaction이 커밋될 때가지 업데이트 내용을 모아두는 1차 캐시 장소
- app의 모든 작업에서 접근할 수 있는 2차 캐시인 공유 캐시를 두고 모든 사용자가 transaction 커밋된 Entity 객체를 볼 수 있다. 항상 Entity를 업데이터하고 업데이트 내용을 DB에 transaction하기 때문에 Entity 내용은 최신 상태를 유지할 수 있다. 그러므로 클라이언트는 꼭 DB에 접속하지 않아도 Entity를 통해 쿼리를 수행할 수 있기 때문에 데이터베이스 조회 횟수를 줄일 수 있다.
1차 캐시 조회시 처음 1차 캐시에 해당 데이터가 있는지 탐색한다. (있으면 바로 리턴), 없으면 데이터베이스에 접근해 값을 탐색한다. 탐색 결과를 바로 리턴하는 것이 아닌 다음 탐색에서 재사용할 수 있도록 1차 캐시에 저장한다. 다만, transaction이 끝나면 1차 캐시도 지워진다. 매우 짧은 순간에 도움이 되기 때문에 실질적으로 데이터베이스 접근량을 줄이진 못한다.
동일성 보장
equality.javaMember findMember1 = entityManager.find(Member.class, 101L); Member findMember2 = entityManager.find(Member.class, 101L); System.out.println(findMember1 == findMember2);MyBatis에서는 조회 결과를 다시 인스턴스로 감싸서 리턴하기 때문에 위 결과는 false가 나오지만, JPA는 1차 캐시에 저장된 같은 참조값을 갖게 해주므로 True가 나온다.
엔티티
등록시 트랜잭션을 지원하는 쓰기 지연 (Transactional Write-Behind) transaction을commit하는 시점에 모든 쿼리가 발생한다. 이렇게 commit 이후에 한번에 쿼리를 날리는 이유는 최적화할 수 있는 여지를 남길 수 있다.엔티티
수정시 변경 감지 (Dirty Checking) Entity를 DTO로 쓸 시 위험한 기능.(값이 변할 때마다 쿼리가 날라갈 수 있기 때문) 1차 캐시에 저장될 때 1차 캐시에는 최초 저장 시점의 SnapShot을 저장해둔다. 만약 변경이 감지되면commit되는 시점에 flush가 호출되면서 JPA가 일일이 각각의 SnapShot을 비교해서 변경을 감지한다. 변경을 감지했다면 UPDATE 쿼리를 쓰기 지연 SQL 저장소에 생성하고 데이터베이스에 반영하고 커밋을 진행한다.
JPQL (java Persistence query language)
SQL이 DB Table을 쿼리한다면, JPQL은 Java Entity 객체를 쿼리한다. JDBC의 문제점인 특정 DB종속되지 않고, Dialect로 각 Navtive 쿼리로 변환한다.
String jpql = "select m From Member m where m.name like '%hello%'";
List<Member> result = em.createQuery(jpql, Member.class).getResultList();
JPA 인터페이스의 3요소
- EntityManagerFactory
- 고객 요청(Thread 하나)마다 EntityManager 생성
- WAS 로드 시점에 하나만 생성하고, WAS 종료할 때 EntityManagerFactory를 닫는다.
- 닫을 때 Connection pooling에 대한 Resource가 Release된다.
- EntityManager
- Persistence Context 내에서 Entity 객체에 대한 CRUD 및 데이터베이스에 동기화 작업 수행
- 쿼리 수행 단위에 해당하며 스레드와 1:1 관계
- 영속성 컨텍스트와 엔티티 생명주기 관리
- EntityTransaction
- Data를 변경하는 모든 작업은 반드시 transaction 안에서 이뤄져야한다.
- tx.begin() : transaction 시작
- tx.commite() : transaction 수행
- tx.rollback() : 작업에 문제 생기면 롤백
JPA 장점
JPA는 JDBC의 반복작업를 제거함으로써 높은 생산성&유지보수성을 얻을 수 있다. JPQL 같이 객체 지향적인 코드를 작성할 수 있고, DB 연결에 대한 관심을 분리해서 비즈니스 로직에 집중할 수 있다. 또한 JPA 인터페이스 추상화를 통해 낮은 DBMS 종속성으로 DBMS 교체 용이성을 높일 수 있다.
Hibernate = JPA 구현체
Hibernate의 구현체는 JPA 인터페이스 3요소를 아래와 같이 구현
- SessionFactory (EntityManagerFactory)
- Session (EntityManager)
- Transaction (EntityTransaction)
Spring Data JPA
JPA의 JPQL을 한번더 추상화시켜서 구현 클래스 없이 인터페이스만 작성해도 컴파일러가 클래스와 쿼리를 완성시킬 수 있다.
Query Method기능은 Spring Data JPA가 메소드 이름을 분석해서 JPQL을 실행한다. 사용자가 Repository 인터페이스에 정해진 규칙대로 메소드를 입력하면, Spring이 알아서 해당 메소드 이름에 적합한 쿼리를 날리는 구현체를 만들어 Bean 등록한다. JPQL을 일일이 작성하는게 아닌 메소드명 만으로 원하는 쿼리를 수행할 수 있게된다. 물론 JPA 추상화한 것이기 때문에 EntityManager를 사용한다.
Query Method 기능
public interface ItemRepository extends JpaRepository<Item, Long> {
Member findByUserName(Stirng username);
}
위와 같이 인터페이스를 정의하면 Entity의 CRUD를 수행할 수 있는 메서드가 기본적으로 생성되고 Query Method를 정의하면 자동으로 Repository Entity 객체에 메서드에 맞는 쿼리를 작성해준다.
Custom Query Method
Query Method로는 join 같은 복잡한 쿼리는 만들 수 없다. 그래서 Custom Query Method를 만들수 있다. Custom Query Method는 Entity나 Mehtod에 JPQL을 작성해놓고, 그 메서드를 실행하면 해당 JPQL을 실행하도록한다. 보통 역할에 맞게 Mehtod에 작성한다.
@Entity
@NamedQuery(
name="Member.findByUsername", // findByUserName 메서드 생성
query="select m from Member m where m.username = ?1"
)
public class Member {
...
}
Prepared statement에 파라미터를 바인딩할 때 위치 기반과 이름 기반이 있는데 위치 기반 보다는 이름 기반이 가독성이 더 좋다.
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("select m from Member m where m.username = :username") // 메서드 옆에 쿼리가 있어서 가독성이 더 좋다.
Member findByUserName(Stirng username);
}
반환 타입
Query Method로 메서드를 선언하면 반환 타입을 단일 객체, Collection 객체, Paging 객체로 반환할 수 있다. 또한 Sort도 지원해서 간단하게 정렬기능도 수행할 수 있다.
Member findByName(String name);
List<Member> findByName(String name);
Page<Member> findByName(String name, Pageable pageable);
List<Member> findByName(String name, Sort sort);
추가적으로 @Async와 @Future를 이용해서 메서드를 비동기 호출하도록 할 수 있다.
Query DSL
Spring Data JPA에서 더 복잡한 쿼리를 작성할 수 있도록 보완하는 기술. 실무에서는 JPQL을 직접 작성한 순간에는 Query DSL을 사용한다. 보통 Spring Data JPA의 JpaReposiitory와 함께 사용한다. 아래는 QueryDSL로 Repository를 작성하는 방법이다.
Type Safety QueryDSL의 경우엔 Query 검증을 컴파일 중에 진행가능, JPQLdms 런타임시에 검증(String으로 구성된 쿼리기 때문)할 수 있기 때문에 QueryDSL은 에러 발생 위험을 낮출 수 있다.
Consistency 일관성 JPA, MongoDB, Scala 어떤 것이든 QueryDSL 사용법은 동일하다.
// 단순히 QueryDSL만 사용할 수 있는 방법
@RequiredArgsConstructor
@Repository
public class UserRepositorySupport{
private final JPAQueryFactory jpaQueryFactory;
public List<User> findByName(String name){
return jpaQueryFactory.selectFrom(QUser.user)
.where(Quser.user.name.trim()).eq(name)
.fetch();
}
}
// Spring Data JPA와 QueryDSL을 모두 사용할 수 있는 방법
public interface UserRepositoryCustom{
List<User> findByName(String name);
}
// QueryDSL 메서드 생성
@RequiredArgsConstructor
public class UserRepositoryCustomImpl implements UserRepositoryCustom{
private final JPAQueryFactory jpaQueryFactory;
@Override
public List<User> findByName(String name){
return jpaQueryFactory.selectFrom(QUser.user)
.where(Quser.user.name.trim()).eq(name)
.fetch();
}
}
// Spring Data JPA의 Query Method와 QueryDSL의 메서드를 모두 사용할 수 있는 방법
public interface UserRepository extends JpaReposiitory<User, Long>, UserRepositoryCustomImpl{
}
(번외) ORM vs SQL Mapper
ORM은 Persistence Context를 통해 Entity 객체를 조작하고, 그것이 DB로 적용되도록 하는 것이다. 따라서 직접 DB에 쿼리를 날리는 JDBC Template의 불편함을 해결하고 메서드로 데이터를 조작할 수 있다. (ORM으로 SQL을 자동으로 생성)
SQL Mapper는 Persistence Context가 없기 때문에 Entity도 없다. Entity 객체가 아닌 그냥 객체와 JDBC 쿼리를 연결한 것이 SQL Mapper다. 그러므로 Entity를 업데이트하면 쿼리가 발생되는 ORM과 달리 그냥 객체기 때문에 업데이트해도 별일이 발생하지 않는다. 보통 레거시 코드가 많고 Native 쿼리를 버리지 못할 경우에 사용한다.